






























































typedef struct {
int N, C, H, W;
unsigned long long output_addr;
unsigned long long input_addr;
} __attribute__((packed)) param_t;
这里默认对c维度进行softmax。
测试用例参数:
param_t params[] = {
{.N = 1, .C = 370, .H = 13, .W = 13 }, // 0
{.N = 1, .C = 1000, .H = 1, .W = 1 }, // 1
{.N = 4, .C = 2, .H = 157, .W = 283}, // 2
{.N = 79, .C = 4090, .H = 1, .W = 1 }, // 3
{.N = 6132, .C = 21, .H = 1, .W = 1 }, // 4
};
一般做法
算丰算子库中没有提供softmax算子,因此需要使用基础算子完成softmax操作。
softmax的表达式为:
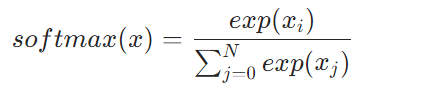
可以看到需要使用的有exp算子,div算子,以及一个跨channel求和的操作。
算丰的算子库也没有提供跨channel求和的操作。这里提供两个思路,一个是使用权重为1.0的1X1卷积,需要多开辟一些空间存放卷积核参数,另一个是由于在计算c维度的softmax的时候,HW的大小并不会有影响,因此,可以将C维度移动到H维度,原本的H,W维度移动到W维度,[N,C,H,W]->[N,1,C,H*W],这样可以通过在新的H维度计算avgpool再乘以元素个数来达到求和的目的。
local_addr_t input_addr, output_addr, sum_addr;
S2L(input_addr, param->addr);
cal_exp(input_addr); // input = exp(input)
cal_sum(sum_addr, input_addr); // sum = input.sum()
div(output_addr, input_addr, sum_addr); // output = input / sum
L2S(param->output_addr, output_addr);
这里的按N切分就比较简单,例如用例4,只需要切分到合适的N就可以完成计算:
local_addr_t input_addr, output_addr, sum_addr;
for(int i=0;i<blocks;i++)
{
S2L(input_addr, param->addr + input_skip_bytes);
cal_exp(input_addr); // input = exp(input)
cal_sum(sum_addr, input_addr); // sum = input.sum()
div(output_addr, input_addr, sum_addr); // output = input / sum
L2S(param->output_addr + output_skip_bytes, output_addr);
}
在softmax中,在使用avgpool计算求和时,由于将C维度移动到了H维度,因此原本的C维度就为1。
但是我们知道,比赛使用的有64个NPU,当C为1时,仅仅会使用第一个NPU进行计算。因此,可以通过将N合理分配到N以及C两个维度,使得既能通过N的切分存放数据,也能够最大利用NPU的算力。
在计算用例2时,由于H和W都为1,因此可以将C维度的4090分摊到H和W维度,将池化由[4090,1]改为[409,10],这样能够加快NPU的计算。
另外,例如用例3,无论怎么调整,C维度的占用都比较少,这时可以调整数据搬入时的stride,使得C维和H维转置,[4,2,157,283]−>[4,157,2,283],这样即可以避免NPU使用不足的问题,也可以避免local memory不够用的问题。