




























































比赛所使用的算丰TPU的架构如下所示:
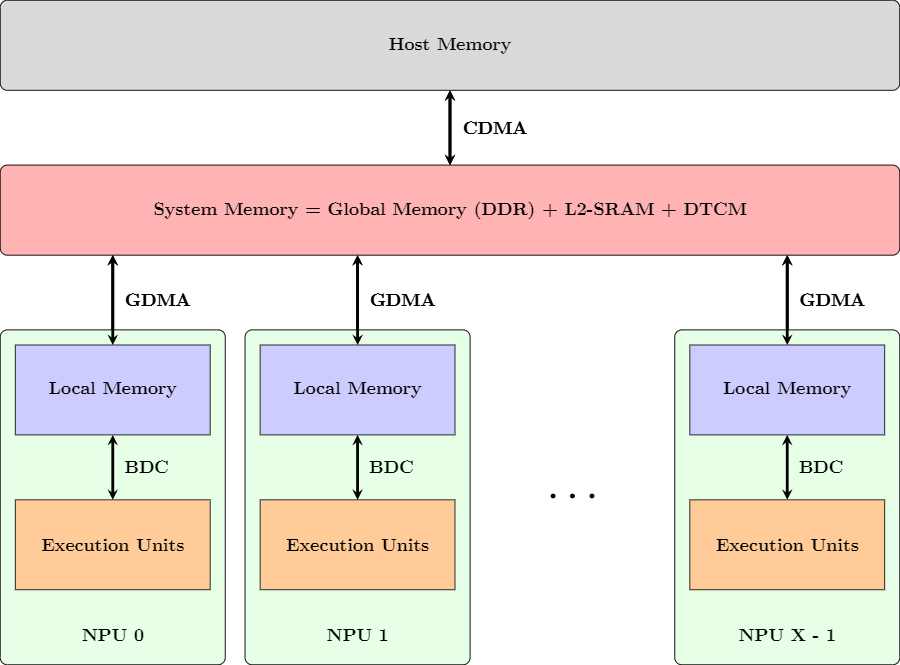
其中host memory为计算机内存,system memory为算丰TPU的内存,local memory为NPU内存。Execution Units(EU)为计算单元。CDMA用于host memory与system memory数据搬运,GDMA用于system momery与local memory之间的数据搬运,BDC用于local memory中数据的计算。
算丰的运算是由指令完成,具体的计算指令由host端发射,device端收到指令执行。其中host memory与system momery的交互由host端代码完成,system memory与local memory的交互由device端代码完成。
比赛需要编写device的代码,也就是关注的是GDMA部分以及BDC的部分,即在local memory和system memory中搬运数据,和使用EU计算数据。
比赛所使用的TPU数据如下:
global memory: 128GB
NPU number: 64
local memory:512KB * 64 = 32MB
EU number: 32bit的EU数量为16
数据在host memory和system memory中的搬运赛事已经提供且无法修改。因此需要选手做的事情简化起来就是:数据从system memory搬入local memory->使用bdc计算->将结果从local memory搬运到system memory。
其中,数据搬运使用的是gdma操作,比赛使用的都是浮点数,因此,搬运一般使用的就是:
void okk_gdma_32bit_cpy_S2L(local_addr_t dst_addr, system_addr_t src_addr, const dim4 *shape, const dim4 *dst_stride, const dim4 *src_stride); //tensor搬入
void okk_gdma_32bit_cpy_L2S(system_addr_t dst_addr, local_addr_t src_addr, const dim4 *shape, const dim4 *dst_stride, const dim4 *src_stride); //tensor搬出
void okk_gdma_32bit_matrix_S2L(local_addr_t dst_addr, system_addr_t src_addr, int rows, int cols, int cols_per_channel, int row_stride); //矩阵搬入
void okk_gdma_32bit_matrix_L2S(system_addr_t dst_addr, local_addr_t src_addr, int rows, int cols, int cols_per_channel, int row_stride); //矩阵搬出
其中local_addr_t表示local memory中的地址,所有local memory为统一寻址。
bdc的相关操作较多,就不一一列举了,详见二元函数,一元函数,神经网络函数。
流程中选手要完成比赛的题目主要分为两部分:数据切分和实现新算子。比赛中的tensor输入有多种大小,因此对特别大的数据需要使用数据切分,每次搬入一部分以完成计算。实现新算子是由于基础的神经网络算子库中提供的算子并不多,例如softmax函数需要自己结合exp算子、池化算子以及除法算子完成。